I was fortunate to be invited to the wonderful (huge) campus of TU Delft earlier this year to give a talk on “Designing for AI.”
I felt a little bit more of an imposter than usual – as I’d left my role in the field nearly a year ago – but it felt like a nice opportunity to wrap up what I thought I’d learned in the last 6 years at Google Research.
Below is the recording of the talk – and my slides with speaker notes.
I’m very grateful to Phil Van Allen and Wing Man for the invitation and support. Thank you Elisa Giaccardi, Alessandro Bozzon, Dave Murray-Rust and everyone the faculty of industrial design engineering at TU Delft for organising a wonderful event.
The excellent talks of my estimable fellow speakers – Elizabeth Churchill, Caroline Sinders and John can be found on the event site here.

Hello!

This talk is mainly a bunch of work from my recent past – the last 5/6 years at Google Research. There may be some themes connecting the dots I hope! I’ve tried to frame them in relation to a series of metaphors that have helped me engage with the engineering and computer science at play.

I won’t labour the definition of metaphor or why it’s so important in opening up the space of designing AI, especially as there is a great, whole paper about that by Dave Murray-Rust and colleagues! But I thought I would race through some of the metaphors I’ve encountered and used in my work in the past.

The term AI itself is best seen as a metaphor to be translated. John Giannandrea was my “grand boss” at Google and headed up Google Research when I joined. JG’s advice to me years ago still stands me in good stead for most projects in the space…

But the first metaphor I really want to address is that of the Optometrist.
This image of my friend Phil Gyford (thanks Phil!) shows him experiencing something many of us have done – taking an eye test in one of those wonderful steampunk contraptions where the optometrist asks you to stare through different lenses at a chart, while asking “Is it better like this? Or like this?”

This comes from the ‘optometrist’ algorithm work by colleagues in Google Research working with nuclear fusion researchers. The AI system optimising the fusion experiments presents experimental parameter options to a human scientist, in the mode of a eye testing optometrist ‘better like this, or like this?’

For me to calls to mind this famous scene of human-computer interaction: the photo enhancer in Blade Runner.
It makes the human the ineffable intuitive hero, but perhaps masking some of the uncanny superhuman properties of what the machine is doing.
The AIs are magic black boxes, but so are the humans!

Which has lead me in the past to consider such AI-systems as ‘magic boxes’ in larger service design patterns.
How does the human operator ‘call in’ or address the magic box?
How do teams agree it’s ‘magic box’ time?
I think this work is as important as de-mystifying the boxes!

Lais de Almeida – a past colleague at Google Health and before that Deepmind – has looked at just this in terms of the complex interactions in clinical healthcare settings through the lens of service design.
How does an AI system that can outperform human diagnosis (Ie the retinopathy AI from deep mind shown here) work within the expert human dynamics of the team?

My next metaphor might already be familiar to you – the centaur.
[Certainly I’ve talked about it before…!]

If you haven’t come across it:
Gary Kasparov famously took on chess-AI Deep Blue and was defeated (narrowly)
He came away from that encounter with an idea for a new form of chess where teams of humans and AIs played against other teams of humans and AIs… dubbed ‘centaur chess’ or ‘advanced chess’
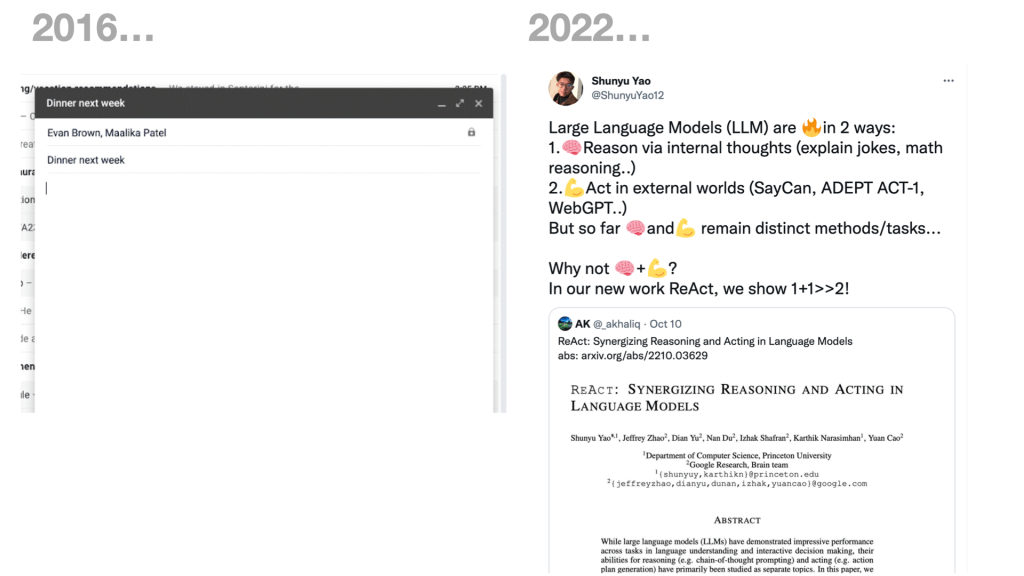
I first started investigating this metaphorical interaction about 2016 – and around those times it manifested in things like Google’s autocomplete in gmail etc – but of course the LLM revolution has taken centaurs into new territory.
This very recent paper for instance looks at the use of LLMs not only in generating text but then coupling that to other models that can “operate other machines” – ie act based on what is generated in the world, and on the world (on your behalf, hopefully)

And notion of a Human/AI agent team is something I looked into with colleagues in Google Research’s AIUX team for a while – in numerous projects we did under the banner of “Project Lyra”.
Rather than AI systems that a human interacts with e.g. a cloud based assistant as a service – this would be pairing truly-personal AI agents with human owners to work in tandem with tools/surfaces that they both use/interact with.

And I think there is something here to engage with in terms of ‘designing the AI we need’ – being conscious of when we make things that feel like ‘pedal-assist’ bikes, amplifying our abilities and reach vs when we give power over to what political scientist David Runciman has described as the real worry. Rather than AI, “AA” – Artificial Agency.
[nb this is interesting on that idea, also]

We worked with london-based design studio Special Projects on how we might ‘unbox’ and train a personal AI, allowing safe, playful practice space for the human and agent where it could learn preferences and boundaries in ‘co-piloting’ experiences.
For this we looked to techniques of teaching and developing ‘mastery’ to adapt into training kits that would come with your personal AI .

On the ‘pedal-assist’ side of the metaphor, the space of ‘amplification’ I think there is also a question of embodiment in the interaction design and a tool’s “ready-to-hand”-ness. Related to ‘where the action is’ is “where the intelligence is”

In 2016 I was at Google Research, working with a group that was pioneering techniques for on-device AI.
Moving the machine learning models and operations to a device gives great advantages in privacy and performance – but perhaps most notably in energy use.
If you process things ‘where the action is’ rather than firing up a radio to send information back and forth from the cloud, then you save a bunch of battery power…
Clips was a little autonomous camera that has no viewfinder but is trained out of the box to recognise what humans generally like to take pictures of so you can be in the action. The ‘shutter’ button is just that – but also a ‘voting’ button – training the device on what YOU want pictures of.

There is a neural network onboard the Clips initially trained to look for what we think of as ‘great moments’ and capture them.
It had about 3 hours battery life, 120º field of view and can be held, put down on picnic tables, clipped onto backpacks or clothing and is designed so you don’t have to decide to be in the moment or capture it. Crucially – all the photography and processing stays on the device until you decide what to do with it.

This sort of edge AI is important for performance and privacy – but also energy efficiency.
A mesh of situated “Small models loosely joined” is also a very interesting counter narrative to the current massive-model-in-the-cloud orthodoxy.

This from Pete Warden’s blog highlights the ‘difference that makes a difference’ in the physics of this approach!

And I hope you agree addressing the energy usage/GHG-production performance of our work should be part of the design approach.

Another example from around 2016-2017 – the on-device “now playing” functionality that was built into Pixel phones to quickly identify music using recognisers running purely on the phone. Subsequent pixel releases have since leaned on these approaches with dedicated TPUs for on-device AI becoming selling points (as they have for iOS devices too!)

And as we know ourselves we are not just brains – we are bodies… we have cognition all over our body.
Our first shipping AI on-device felt almost akin to these outposts of ‘thinking’ – small, simple, useful reflexes that we can distribute around our cyborg self.

And I think this approach again is a useful counter narrative that can reveal new opportunities – rather than the centralised cloud AI model, we look to intelligence distributed about ourselves and our environment.

A related technique pioneered by the group I worked in at Google is Federated Learning – allowing distributed devices to train privately to their context, but then aggregating that learning to share and improve the models for all while preserving privacy.
This once-semiheretical approach has become widespread practice in the industry since, not just at Google.

My next metaphor builds further on this thought of distributed intelligence – the wonderful octopus!

I have always found this quote from ETH’s Bertrand Meyer inspiring… what if it’s all just knees! No ‘brains’ as such!!!

In Peter Godfrey-Smith’s recent book he explores different models of cognition and consciousness through the lens of the octopus.
What I find fascinating is the distributed, embodied (rather than centralized) model of cognition they appear to have – with most of their ‘brains’ being in their tentacles…

And moving to fiction, specifically SF – this wonderful book by Adrian Tchaikovsky depicts an advanced-race of spacefaring octopi that have three minds that work in concert in each individual. “Three semi-autonomous but interdependent components, an “arm-driven undermind (their Reach, as opposed to the Crown of their central brain or the Guise of their skin)”


I want to focus on the that idea of ‘guise’ from Tchaikovsky’s book – how we might show what a learned system is ‘thinking’ on the surface of interaction.

We worked with Been Kim and Emily Reif in Google research who were investigating interpretability in modest using a technique called Tensor concept activation vectors or TCAVs – allowing subjectivities like ‘adventurousness’ to be trained into a personalised model and then drawn onto a dynamic control surface for search – a constantly reacting ‘guise’ skin that allows a kind of ‘2-player’ game between the human and their agent searching a space together.
We built this prototype in 2018 with Nord Projects.

This is CavCam and CavStudio – more work using TCAVS by Nord Projects again, with Alison Lentz, Alice Moloney and others in Google Research examining how these personalised trained models could become reactive ‘lenses’ for creative photography.
There are some lovely UI touches in this from Nord Projects also: for instance the outline of the shutter button glowing with differing intensity based on the AI confidence.

Finally – the Rubber Duck metaphor!

You may have heard the term ‘rubber duck debugging’? Whereby your solve your problems or escape creative blocks by explaining out-loud to a rubber duck – or in our case in this work from 2020 and my then team in Google Research (AIUX) an AI agent.
We did this through the early stages of covid where we felt keenly the lack of informal dialog in the studio leading to breakthroughs. Could we have LLM-powered agents on hand to help make up for that?

And I think that ‘social’ context for agents in assisting creative work is what’s being highlighted here by the founder of MidJourney, David Holz. They deliberated placed their generative system in the social context of discord to avoid the ‘blank canvas’ problem (as well as supercharge their adoption) [reads quote]

But this latest much-discussed revolution in LLMs and generative AI is still very text based.
What happens if we take the interactions from magic words to magic canvases?
Or better yet multiplayer magic canvases?

There’s lots of exciting work here – and I’d point you (with some bias) towards an old intern colleague of ours – Gerard Serra – working at a startup in Barcelona called “Fermat”

So finally – as I said I don’t work at this as my day job any more!
I work for a company called Lunar Energy that has a mission of electrifying homes, and moving us from dependency on fossil fuels to renewable energy.
We make solar battery systems but also AI software that controls and connects battery systems – to optimise them based on what is happening in context.

For example this recent (September 2022) typhoon warning in Japan where we have a large fleet of batteries controlled by our Gridshare platform.
You can perhaps see in the time-series plot the battery sites ‘anticipating’ the approach of the typhoon and making sure they are charged to provide effective backup to the grid.

And I’m biased of course – but think most of all this is the AI we need to be designing, that helps us at planetary scale – which is why I’m very interested by the recent announcement of the https://antikythera.xyz/ program and where that might also lead institutions like TU Delft for this next crucial decade toward the goals of 2030.


[…] core argument (which I’ve made in the Netherlands before…): we’ve spent too much time trying to make AI interfaces look and behave like humans, when […]